
In the ever-evolving landscape of data management, two terms often pop up in conversations among data professionals: Data Warehouses and Data Reservoirs. But what are they, and how do they differ? Let’s dive deep into the world of data storage to find out.
—————————————————–
TL;DR: Data Warehouses and Data Reservoirs are both essential data storage systems, but they serve different purposes. While Data Warehouses are structured and optimized for querying, Data Reservoirs offer vast storage and flexibility. The choice between them depends on the specific needs of a business, with Warehouses being ideal for structured analytics and Reservoirs for diverse, raw data storage.
| Feature/Aspect | Data Warehouse | Data Reservoir |
|---|---|---|
| Primary Purpose | Structured data storage for analytics | Vast storage of raw, unstructured data |
| Data Structure | Highly structured | Flexible, often unstructured |
| Schema | Schema-on-write (defined before storage) | Schema-on-read (defined at the time of reading) |
| Data Processing | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Optimization | Optimized for querying | Optimized for storage |
| Data Quality | High due to stringent checks | Varies, can become a “data swamp” without governance |
| Cost & Maintenance | Can be high due to infrastructure and optimizations | Often lower initial costs, but requires management |
| Use Cases | Business Intelligence, Reporting | Big Data projects, Machine Learning |
| Scalability | Limited by infrastructure | Highly scalable due to distributed nature |
| Data Integration | Requires integration tools | Can ingest diverse data sources directly |
Introduction: The Age of Information
We live in an era where data is generated at an unprecedented rate. From businesses to individuals, the need to store, manage, and analyze data has never been more crucial. This has given rise to various data storage solutions, each with its unique features and benefits.
Chapter 1: The Traditional Data Warehouse
1.1 A Structured Approach
In the vast realm of data management, the Data Warehouse stands out as a beacon of order and structure. But what does this really mean? Let’s break it down.
Foundation of Relational Databases
At its core, a Data Warehouse is built upon the principles of relational databases. This means that data is stored in tables, with rows and columns, much like a spreadsheet. Each table represents a specific entity, such as customers, products, or sales, and the relationships between these tables are well-defined. This interconnected web of tables allows for efficient querying and data retrieval.
Data Modeling Techniques
Before data even enters the warehouse, there’s a meticulous process of data modeling. This involves designing the structure of the warehouse to ensure it aligns with business needs. Techniques such as star schema or snowflake schema are employed to optimize data retrieval and simplify complex queries. These schemas revolve around central fact tables (which contain transactional data) and dimension tables (which contain descriptive, attribute data).
Consistency and Integrity
One of the hallmarks of the structured approach is the emphasis on data consistency and integrity. Data Warehouses enforce data integrity constraints, such as primary keys and foreign keys, to ensure that the data is accurate and consistent. This means no duplicate records, no missing values, and no unlinked data.
Historical Data Storage
Unlike operational databases that focus on current data, Data Warehouses are designed to store historical data. This allows businesses to track changes over time, analyze trends, and make future predictions. The structured approach ensures that this historical data is stored in a way that’s both consistent with current data and easily accessible for analysis.
Optimized for Analysis
The structured nature of Data Warehouses isn’t just for show. It’s purposefully designed to support analytical processing. With data neatly organized and relationships clearly defined, running complex analytical queries becomes faster and more efficient. This ensures that business analysts and decision-makers can quickly extract the insights they need without wading through a sea of unstructured data.
In essence, the structured approach of Data Warehouses is all about creating a stable, organized, and efficient environment for data storage and analysis. It’s a testament to the idea that with a solid foundation, you can build powerful analytical capabilities that drive informed business decisions.
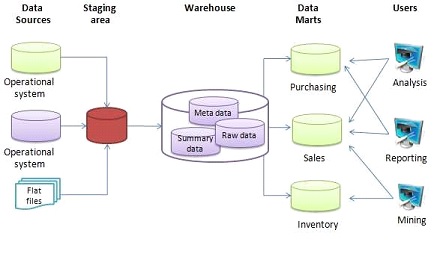
1.2 Schema-on-Write: The Blueprint
The term “Schema-on-Write” might sound like tech jargon, but it’s a foundational concept that defines the very essence of Data Warehouses. Let’s unpack this term and understand its implications.
The Blueprint Analogy
Imagine constructing a building. Before laying the first brick, you’d need a detailed blueprint that outlines the design, dimensions, and placement of every room, door, and window. Similarly, in a Data Warehouse, before you store any data, you define a schema—a blueprint that dictates how data will be organized, related, and stored.
Predefined Structure
In the Schema-on-Write approach, the structure of the data (the schema) is determined before writing the data into the warehouse. This means you decide in advance what tables you’ll have, what columns each table will contain, and how these tables will relate to each other. It’s a proactive approach, ensuring that data conforms to a specific format and structure as it’s ingested.
Data Validation and Integrity
One of the significant advantages of this approach is that data is validated against the schema as it’s written into the warehouse. This ensures that the data adheres to predefined data types, constraints, and relationships. For instance, if a column is defined to hold dates, the warehouse will reject any data for that column that isn’t in a date format. This validation ensures data integrity and consistency.
Performance Benefits
Because the structure is predefined, Data Warehouses can optimize storage and query performance. The system knows exactly where to place data and how to retrieve it efficiently, leading to faster query response times. It’s like knowing precisely where you’ve kept your keys in a well-organized room, allowing for quick access.
Trade-offs
While Schema-on-Write offers numerous benefits, it also comes with trade-offs. The upfront effort required to define the schema can be substantial. Additionally, making changes to the schema once data is written can be complex and time-consuming. It demands careful planning and foresight to anticipate future data needs and design the schema accordingly.
In conclusion, the Schema-on-Write approach is akin to laying a solid foundation before building a house. It requires meticulous planning and design but ensures a robust, efficient, and consistent data storage system. It’s a testament to the adage: “Well begun is half done.”
1.3 The ETL Process: Data’s Journey
The ETL process, standing for Extract, Transform, Load, is the unsung hero behind the scenes of every Data Warehouse. It’s the bridge that transports raw data from its source, refines it, and then systematically stores it in the warehouse. Let’s embark on this transformative journey of data.
Extract: The Initial Lift-Off
- Data Sources: The extraction phase begins with identifying and accessing various data sources. These sources can range from databases, CRM systems, and ERP systems to flat files, weblogs, and even real-time data streams.
- Data Retrieval: The process involves pulling or extracting the data from these sources. It’s crucial to ensure that this extraction doesn’t disrupt the source systems, especially if they are transactional systems serving live users.
- Initial Cleansing: At this stage, any glaring inconsistencies, errors, or missing values might be addressed to ensure that the data is in a suitable state for transformation.
Transform: The Crucible of Refinement
- Data Mapping: As data is moved from source systems to the Data Warehouse, it often needs to be reshaped or mapped. This could involve translating codes, converting currency, or even aggregating data.
- Data Cleaning: This step is vital to ensure data quality. It involves identifying and rectifying errors, filling in missing values, and resolving inconsistencies.
- Data Enrichment: Sometimes, the raw data might be enhanced with additional data to make it more valuable. For example, geographical coordinates might be added based on address data.
- Format Structuring: Data might be converted into formats suitable for the Data Warehouse. This could involve date format changes, text standardization, or numerical conversions.
Load: The Final Destination
- Populating the Warehouse: Once the data is extracted and transformed, it’s ready to be loaded into the Data Warehouse. This step involves writing the data into the warehouse’s tables.
- Incremental vs. Full Loads: Depending on the volume of data and the requirements, this loading can be a full load (where all data is loaded) or an incremental load (where only new or changed data is loaded).
- Performance Considerations: Loading data, especially in large volumes, needs to be optimized to ensure it’s done efficiently without overloading the system. This might involve techniques like batch processing or parallel loading.
- Data Validation: Post-loading, checks are often performed to ensure that the data has been loaded correctly and completely. Any discrepancies can then be addressed.
In essence, the ETL process is a meticulous journey that raw data undertakes to transform into meaningful, structured, and high-quality information in a Data Warehouse. It’s a testament to the importance of not just storing data, but ensuring that it’s in the right shape, form, and quality to derive valuable insights.
1.4 Optimized for Querying
In the realm of data management, simply storing vast amounts of data isn’t enough. The real value lies in retrieving specific subsets of that data swiftly and efficiently to derive insights. Data Warehouses, with their structured approach, are specifically designed and optimized for this purpose. Let’s explore how.
Structured for Speed
- Indexing: One of the primary techniques used to speed up data retrieval is indexing. Just like an index in a book helps you quickly locate specific information, database indexes allow for rapid data lookups without scanning every row in a table.
- Partitioning: Data Warehouses often employ partitioning, where large tables are divided into smaller, more manageable pieces, yet treated as a single table. When queries are executed, instead of searching the entire table, the system can target specific partitions, accelerating the retrieval process.
Tailored for Analytical Processing
- Columnar Storage: Unlike traditional databases that store data row by row, some modern Data Warehouses use columnar storage, storing each table’s data column by column. This is particularly beneficial for analytical queries that often retrieve specific columns but not all rows.
- Aggregation: Data Warehouses are optimized to perform aggregations (like SUM, AVG, COUNT) efficiently. This is crucial for analytical tasks where you might want to compute metrics across vast datasets.
Optimized Query Execution
- Query Caching: To speed up frequent queries, Data Warehouses can cache the results of previous queries. If the same query is run again, the system can fetch the result from the cache instead of processing the query anew.
- Parallel Processing: Many advanced Data Warehouses leverage parallel processing, where a query is divided into smaller tasks that are executed simultaneously across multiple processors or nodes. This parallelism can drastically reduce query execution time.
Adaptable to Evolving Needs
- Scalability: As data volumes grow, so does the complexity of queries. Modern Data Warehouses are designed to scale, ensuring that as data inflow increases, query performance remains optimal.
- Tuning and Maintenance: Over time, as data patterns and query patterns evolve, Data Warehouses may require tuning. This could involve updating indexes, reorganizing storage, or even tweaking the schema to ensure that querying remains swift and efficient.
In conclusion, a Data Warehouse isn’t just a passive repository for data; it’s a dynamic system, meticulously designed and continuously optimized to ensure that data retrieval is as swift and efficient as data storage. It underscores the principle that data, no matter how vast, is only as valuable as the insights it can provide—and those insights are derived from efficient querying.
1.5 Cost and Maintenance
The decision to implement a Data Warehouse is not just a technical one; it’s also a financial commitment. Beyond the initial setup, the ongoing costs and maintenance play a significant role in the total cost of ownership (TCO) of a Data Warehouse. Let’s explore these facets in detail.
Initial Setup Costs
- Hardware and Infrastructure: Traditional Data Warehouses, especially on-premises ones, require substantial investment in hardware. This includes servers, storage devices, networking equipment, and backup systems.
- Software Licensing: Whether it’s the database management system (DBMS) or related tools, software licensing can be a significant portion of the initial costs.
- Design and Implementation: The process of designing the schema, setting up the ETL processes, and integrating with other systems requires expertise. Hiring consultants or dedicating internal resources can add to the initial expenses.
Operational Costs
- Storage: As data volumes grow, so does the need for storage. While storage costs have been decreasing over the years, it still represents a recurring cost, especially for large enterprises.
- Compute Resources: Running complex queries, especially on large datasets, requires computational power. Ensuring that the Data Warehouse can handle peak loads without performance degradation can add to operational costs.
- Licensing Renewals: Many software solutions associated with Data Warehouses come with recurring licensing fees, which need to be factored into the operational costs.
Maintenance and Upkeep
- Regular Backups: To safeguard against data loss, regular backups are essential. This not only requires additional storage but also tools and resources to manage and test backups.
- Performance Tuning: Over time, as data and query patterns evolve, the Data Warehouse may need tuning. This could involve re-indexing, optimizing queries, or even restructuring data.
- Updates and Patches: Keeping the software up-to-date with the latest patches and versions is crucial for security and performance. This involves testing and downtime, which can have associated costs.
- Scaling: As the business grows and data inflow increases, the Data Warehouse might need to scale, either vertically (more powerful hardware) or horizontally (adding more nodes). Scaling involves both costs and complexities.
Human Resources
- Training: Ensuring that the IT team is well-versed with the Data Warehouse technologies requires regular training, especially when new features or tools are introduced.
- Administration: A dedicated team is often required to manage, monitor, and ensure the smooth operation of the Data Warehouse. This includes database administrators, ETL developers, and security experts.
In conclusion, while Data Warehouses offer immense value in terms of data consolidation, analytics, and business intelligence, they come with associated costs and maintenance challenges. It’s essential for organizations to be aware of these aspects, plan accordingly, and ensure that the benefits derived from the Data Warehouse justify the investments made.
Chapter 2: The Versatile Data Reservoir
2.1 A Repository for All
In the vast digital universe, data comes in myriad shapes and sizes. From neatly tabulated spreadsheets to messy social media posts, from high-resolution images to streaming sensor data, the variety is staggering. Enter the Data Reservoir (often termed Data Lake) – a versatile storage solution designed to embrace this diversity. Let’s explore its inclusive nature.
Embracing Diversity
- Structured Data: Just like traditional databases and Data Warehouses, Data Reservoirs can store structured data. This includes relational data with well-defined schemas, such as tables from transactional systems or CSV files.
- Semi-Structured Data: This category includes formats like JSON, XML, and YAML. While they have some level of structure, they don’t fit neatly into the traditional table-row-column paradigm. Data Reservoirs can ingest and store these formats natively, preserving their inherent structure.
- Unstructured Data: Think of vast text documents, images, videos, audio files, and more. Unlike structured databases, which would struggle with this kind of data, Data Reservoirs can store it without breaking a sweat.
Scalability at Its Core
- Volume: One of the standout features of Data Reservoirs is their ability to scale horizontally. As data volumes grow, you can simply add more storage. This makes them ideal for organizations that generate or collect vast amounts of data.
- Variety: Beyond just volume, Data Reservoirs are designed to handle a wide variety of data types and formats. Whether it’s time-series data from IoT devices, logs from web servers, or social media feeds, the reservoir is equipped to store it all.
Raw and Processed Data Coexistence
- Immutable Raw Data: One common practice is to store raw data in its original, immutable form. This ensures that you always have a pristine copy of the data, untouched by any transformations or processing.
- Processed Data Zones: Alongside raw data, Data Reservoirs often have zones or areas dedicated to processed or refined data. This could be aggregated data, data enriched with additional sources, or data transformed into a more query-friendly format.
Metadata and Cataloging
- Organizing the Reservoir: Given the diverse nature of data in the reservoir, metadata becomes crucial. Metadata is data about data – it provides context, meaning, and organization. It might include information about the data’s source, its format, when it was ingested, and more.
- Data Catalogs: To make data discoverable and usable, many Data Reservoirs implement data catalogs. These are like directories or indexes, helping users find the data they need and understand its context.
In essence, a Data Reservoir is like a vast digital library, designed to accommodate every conceivable type of data. It’s not just about storage; it’s about creating a unified, organized, and accessible repository where data, in all its diverse glory, can coexist harmoniously. Whether you’re a data scientist looking for raw datasets to experiment with, or a business analyst seeking refined data for reports, the reservoir stands ready to serve.

2.2 Schema-on-Read: Flexibility First
In the world of data storage and retrieval, the moment of defining structure is pivotal. While traditional Data Warehouses employ a “Schema-on-Write” approach, Data Reservoirs champion the “Schema-on-Read” paradigm. This shift offers a new level of flexibility and adaptability. Let’s explore how.
Deferring Structure
- Store Now, Define Later: The essence of Schema-on-Read is the idea of storing data first and defining its structure later, at the time of reading or analysis. This means data can be ingested into the reservoir in its raw, native format without the need for an immediate schema definition.
- Adaptable to Change: By not committing to a schema upfront, Data Reservoirs can easily adapt to evolving data sources and structures. If a source changes its data format or introduces new fields, the reservoir can accommodate without major overhauls.
Empowering Analysts and Data Scientists
- Tailored Schemas: Different analysts or applications might interpret and use the same data differently. With Schema-on-Read, each user or application can define a schema tailored to its specific needs when accessing the data.
- Exploratory Analysis: For data scientists and analysts who often engage in exploratory data analysis, the flexibility to define and redefine schemas on-the-fly is invaluable. It allows them to experiment, iterate, and discover insights without being constrained by a rigid schema.
Performance Considerations
- Processing Overhead: One trade-off with Schema-on-Read is the potential processing overhead at query time. Since the schema is applied during data retrieval, queries might take longer compared to systems where data is pre-structured.
- Optimized Storage Formats: To mitigate performance challenges, many Data Reservoirs support optimized storage formats like Parquet or ORC. These formats allow for efficient columnar storage and compression, speeding up Schema-on-Read operations.
Ensuring Data Quality
- Metadata and Documentation: Given the deferred schema definition, maintaining comprehensive metadata and documentation becomes crucial. This ensures that users can understand the data’s context, source, and potential quirks when they define their schemas.
- Validation Tools: While the schema is applied on read, it’s essential to have tools and processes in place to validate data quality. This might involve checking for missing values, outliers, or inconsistencies in the raw data.
In conclusion, Schema-on-Read is a testament to the adaptability and flexibility of Data Reservoirs. It’s a paradigm shift that empowers users, fosters experimentation, and accommodates the dynamic nature of today’s data sources. While it comes with its challenges, the benefits of agility and adaptability often outweigh the trade-offs, especially in fast-evolving data landscapes.
2.3 Storage vs. Processing
In the digital age, data is often likened to oil—a valuable resource that, when refined, powers decision-making and innovation. However, storing this “oil” is only half the equation. Processing it to extract meaningful insights is equally crucial. Data Reservoirs, with their vast storage capabilities, also integrate with powerful processing frameworks. Let’s dissect the interplay between storage and processing.
The Storage Paradigm
- Vast and Varied: Data Reservoirs are designed to store petabytes of data, accommodating a wide spectrum from structured datasets to unstructured blobs like images and videos.
- Economical Scalability: One of the hallmarks of Data Reservoirs, especially cloud-based ones, is the ability to scale storage economically. As data inflows increase, additional storage can be provisioned without hefty costs.
- Data Immutability: Often, raw data stored in reservoirs is immutable, meaning once written, it doesn’t change. This ensures a consistent historical record, enabling accurate backtracking and analysis.
Beyond Storage: The Processing Might
- Distributed Processing: Given the volume of data, traditional processing methods fall short. Data Reservoirs often integrate with distributed processing frameworks like Apache Hadoop or Apache Spark. These frameworks can process data across clusters of machines in parallel, ensuring timely results even for complex computations.
- ETL vs. ELT: While traditional Data Warehouses often follow an ETL (Extract, Transform, Load) approach, Data Reservoirs enable an ELT (Extract, Load, Transform) paradigm. Data is first loaded into the reservoir and then transformed using powerful processing engines.
- Real-time Processing: Beyond batch processing, modern Data Reservoirs support real-time data processing. This is crucial for use-cases like fraud detection, where insights need to be derived from data streams in real-time.
Optimizing the Interplay
- Data Partitioning: Organizing data into logical partitions can significantly speed up processing. For instance, if data is partitioned by date, a query targeting a specific date range can swiftly access relevant partitions without scanning the entire dataset.
- In-memory Processing: Technologies like Apache Spark leverage in-memory processing, where data is loaded into RAM instead of being read from disk. This dramatically accelerates processing speeds.
- Unified Platforms: Some modern platforms unify storage and processing, ensuring seamless integration and optimization. This tight coupling can lead to performance enhancements and simplified data operations.
In essence, while Data Reservoirs serve as vast repositories, their true potential is unlocked when coupled with robust processing capabilities. It’s a symbiotic relationship where storage provides the raw material, and processing refines it into actionable insights. In the ever-evolving data landscape, striking the right balance between storage and processing is key to harnessing the full power of data.
2.4 Data Governance and Data Quality
In the vast expanse of a Data Reservoir, where data from myriad sources coexists, ensuring governance and maintaining data quality become paramount. Without these, the reservoir risks becoming a chaotic “data swamp,” diminishing its value. Let’s explore the pillars of governance and the essence of quality in this context.
Data Governance: Steering the Ship
- Access Control: With potentially sensitive data stored in the reservoir, it’s essential to have robust access control mechanisms. This ensures that only authorized individuals can access specific datasets, safeguarding data privacy and security.
- Audit Trails: Keeping a record of who accessed what data and when provides transparency and accountability. Audit trails are crucial for regulatory compliance and for investigating any anomalies or breaches.
- Data Lineage: Understanding where data comes from, its journey through various processing stages, and its eventual destination is vital. Data lineage tools provide a visual representation of this journey, aiding in impact analysis and tracing back errors.
- Metadata Management: Metadata, often termed “data about data,” provides context. Managing metadata effectively ensures that users can understand data’s source, its transformations, and its relevance, making data discovery and usage more efficient.
Ensuring Data Quality
- Validation and Cleansing: As data is ingested into the reservoir, it’s essential to validate it against predefined quality rules. This might involve checking for missing values, outliers, or inconsistencies and then cleansing the data to rectify these issues.
- Deduplication: Especially in large datasets, there’s a risk of duplicate records. Deduplication processes identify and remove these redundancies, ensuring data integrity.
- Standardization: Data coming from various sources might be in different formats or units. Standardizing data—be it date formats, currency conversions, or text casing—ensures consistency across the reservoir.
- Quality Metrics and Dashboards: Continuously monitoring data quality is crucial. Implementing dashboards that showcase quality metrics, such as error rates, missing values, or freshness, provides a real-time view into the state of data in the reservoir.
Balancing Flexibility and Control
- Schema Evolution: While Data Reservoirs offer flexibility with the Schema-on-Read approach, there’s still a need to manage schema changes, especially for processed or refined datasets. Tools that handle schema evolution ensure that changes are tracked and managed without disrupting downstream applications.
- Data Cataloging: Given the vastness of the reservoir, finding relevant data can be like finding a needle in a haystack. Data catalogs, which index and categorize data, make discovery easier, ensuring users can find and utilize data effectively.
In conclusion, while Data Reservoirs offer unparalleled flexibility and scalability, it’s the pillars of governance and the relentless pursuit of quality that ensure they remain valuable assets. Without governance, a reservoir can quickly become unruly; without quality, its insights can become questionable. Balancing the two is the key to harnessing the true potential of a Data Reservoir.
Chapter 3: Comparative Insights
3.1 Use Cases and Applications
In today’s data-driven landscape, both Data Warehouses and Data Reservoirs play pivotal roles in diverse scenarios. Their unique architectures and capabilities make them suitable for specific applications. Let’s explore some of the prominent use cases for each.
Data Warehouses: Structured Analysis Powerhouse
- Business Intelligence (BI) Reporting: One of the primary applications of Data Warehouses is BI reporting. Organizations rely on BI tools to generate dashboards, visualizations, and reports that provide insights into business performance, sales metrics, customer behavior, and more.
- Historical Data Analysis: Data Warehouses are adept at storing historical data, enabling businesses to perform trend analysis, year-over-year comparisons, and retrospective studies to identify patterns and make informed decisions.
- Customer Relationship Management (CRM): CRMs often integrate with Data Warehouses to analyze customer data, segment users, and derive insights to enhance customer experiences and drive sales.
- Supply Chain Optimization: By analyzing data from various stages of the supply chain, businesses can optimize inventory levels, predict demand, and streamline operations, all powered by the structured data in their Data Warehouses.
Data Reservoirs: The Versatile Data Playground
- Big Data Analytics: Given their ability to store vast and varied datasets, Data Reservoirs are ideal for big data analytics. Whether it’s analyzing social media feeds, web logs, or sensor data, reservoirs provide the raw material for deep insights.
- Machine Learning and AI: Data scientists and ML engineers often tap into Data Reservoirs for training datasets. The diverse data stored in reservoirs can be used to train, test, and validate machine learning models.
- Real-time Analytics: Modern Data Reservoirs, equipped with real-time processing capabilities, can provide insights on-the-fly. This is crucial for applications like fraud detection, real-time recommendation systems, or monitoring IoT device networks.
- Data Exploration and Discovery: The flexible nature of Data Reservoirs makes them ideal playgrounds for data exploration. Analysts and scientists can dive into raw data, experiment with different schemas, and discover new insights without the constraints of a rigid structure.
- Data Archival and Backup: Beyond analytics, Data Reservoirs can serve as cost-effective archival solutions. Organizations can dump older, less frequently accessed data into the reservoir, ensuring it’s available if needed, without incurring high storage costs.
In essence, while there’s some overlap in the applications of Data Warehouses and Data Reservoirs, their distinct architectures make them uniquely suited for specific scenarios. Data Warehouses, with their structured and optimized design, are powerhouses for traditional analytics and BI. In contrast, Data Reservoirs, with their vast and flexible nature, cater to a broader spectrum of applications, from big data analytics to machine learning. Both are indispensable tools in the modern data ecosystem, serving complementary roles in driving data-driven decision-making.
3.2 Scalability and Growth
In the ever-evolving digital landscape, the ability to scale and adapt to growing data volumes and demands is crucial. Both Data Warehouses and Data Reservoirs face challenges and opportunities in this arena. Let’s explore how each handles scalability and supports organizational growth.
Data Warehouses: Precision Engineering
- Vertical Scalability: Traditional Data Warehouses often scale vertically, meaning they rely on more powerful hardware (e.g., faster CPUs, more RAM) to handle increased loads. While effective to a point, this approach can become expensive and has its limits.
- Optimized Storage: Data Warehouses are designed for efficient querying. This means data is often stored in ways (like columnar storage) that speed up specific query types. As data grows, maintaining this optimized storage becomes crucial.
- Partitioning and Indexing: To manage large datasets, Data Warehouses employ techniques like partitioning (breaking data into manageable chunks) and indexing (creating pointers to data) to ensure queries remain fast.
- Challenges with High Ingest Rates: Traditional Data Warehouses can struggle with very high data ingest rates. The structured nature of the warehouse means that ingesting data requires careful transformation and integration, which can be time-consuming.
Data Reservoirs: Built for Volume and Variety
- Horizontal Scalability: Data Reservoirs, especially those built on distributed systems like Hadoop, are designed for horizontal scalability. This means they can expand by adding more nodes to the system, distributing data and processing across them. This approach is more cost-effective and can handle vast data volumes.
- Flexible Storage: Unlike the structured storage of Data Warehouses, Data Reservoirs can store data in its native format. This flexibility means they can easily accommodate growing data without the need for extensive redesign.
- Adapting to Data Variety: As organizations tap into new data sources, from IoT devices to social media feeds, Data Reservoirs can ingest this varied data without missing a beat.
- Elasticity in the Cloud: Modern Data Reservoirs, especially those hosted in cloud environments, offer elasticity. They can automatically scale resources up or down based on demand, ensuring optimal performance while managing costs.
Growth Considerations for Organizations
- Infrastructure Costs: As data volumes grow, so do infrastructure costs. Organizations need to consider the total cost of ownership, including hardware, software, maintenance, and operational costs.
- Talent and Expertise: Scaling systems isn’t just about technology. It requires skilled personnel to manage, maintain, and optimize these systems. As the data ecosystem grows, investing in talent becomes crucial.
- Future-Proofing: With the rapid advancements in technology, what’s cutting-edge today might become obsolete tomorrow. Organizations need to ensure that their data infrastructure is adaptable and can integrate with future technologies.
In conclusion, while both Data Warehouses and Data Reservoirs offer scalability, they approach it differently. Data Warehouses focus on structured, optimized storage and might scale vertically, while Data Reservoirs embrace volume and variety, scaling horizontally. As organizations chart their growth paths, understanding these scalability nuances can guide informed infrastructure decisions.
3.3 Data Quality and Management
Data is often hailed as the new oil, but like crude oil, it needs refining to be valuable. Ensuring data quality and effective management is paramount for both Data Warehouses and Data Reservoirs. Let’s delve into how each system approaches these critical aspects.
Data Warehouses: Precision and Consistency
- Data Validation: Before data enters a Data Warehouse, it undergoes rigorous validation. This ensures that the data conforms to predefined formats, ranges, and standards, ensuring consistency.
- Data Cleansing: Any anomalies, inconsistencies, or errors detected during validation are rectified through data cleansing processes. This might involve removing duplicates, correcting values, or imputing missing data.
- Master Data Management (MDM): Data Warehouses often integrate with MDM systems to ensure that critical data entities, like customers or products, are consistently defined and managed across the organization.
- Change Data Capture (CDC): As source systems evolve, CDC mechanisms track and capture changes, ensuring the Data Warehouse remains updated and reflects the current state of source systems.
Data Reservoirs: Embracing Diversity with Quality
- Raw Data Preservation: One of the hallmarks of Data Reservoirs is the preservation of raw data. By storing data in its original form, organizations have a pristine, unaltered record, which can be invaluable for traceability and auditing.
- Quality Layers: While raw data is preserved, Data Reservoirs often implement layers or zones of quality. Data might move from a raw zone to a cleansed or refined zone after undergoing quality checks and transformations.
- Metadata Management: Given the diverse nature of data in the reservoir, metadata (data about data) becomes crucial. Metadata provides context, lineage, and descriptions, helping users understand and trust the data they’re working with.
- Data Cataloging: To ensure data discoverability and usability, Data Reservoirs often implement data catalogs. These catalogs index, categorize, and annotate data, making it easier for users to find relevant datasets.
Unified Data Management Considerations
- Data Stewardship: Assigning data stewards or guardians who are responsible for specific data domains ensures accountability. These stewards oversee data quality, metadata management, and ensure compliance with data policies.
- Automated Quality Checks: Implementing automated tools that continuously monitor and check data quality can catch issues early. These tools can validate data against rules, detect anomalies, and even auto-correct certain issues.
- Feedback Loops: Creating mechanisms where users can report data issues or provide feedback ensures continuous improvement. This feedback can be invaluable in refining data processes and enhancing quality over time.
In essence, while the structured nature of Data Warehouses inherently demands rigorous data quality and management processes, Data Reservoirs, with their vast and varied datasets, require a more layered and metadata-driven approach. Regardless of the system, the end goal remains the same: ensuring that data is accurate, reliable, and trustworthy, empowering organizations to derive meaningful and actionable insights.

Chapter 4: Practical Implications
4.1 Business Decision Making
In today’s competitive business landscape, making informed decisions is not just a luxury—it’s a necessity. Both Data Warehouses and Data Reservoirs play pivotal roles in equipping businesses with the insights they need to navigate challenges and seize opportunities. Let’s explore how these systems influence and enhance business decision-making.
Data Warehouses: The Structured Insight Engine
- Historical Analysis: With their ability to store structured historical data, Data Warehouses enable businesses to look back in time. This retrospective view allows for trend analysis, year-over-year comparisons, and understanding past performance to predict future trajectories.
- Key Performance Indicators (KPIs): Data Warehouses often power Business Intelligence (BI) tools that track and visualize KPIs. Whether it’s sales metrics, customer retention rates, or operational efficiencies, these KPIs provide a pulse on the business’s health.
- Segmentation and Targeting: By analyzing customer data, businesses can segment their audience based on behavior, preferences, or demographics. This segmentation drives targeted marketing campaigns, personalized experiences, and tailored product offerings.
- Forecasting and Predictive Analysis: Using historical data as a foundation, Data Warehouses can support forecasting models. These models predict future sales, market demands, or inventory levels, helping businesses plan and allocate resources effectively.
Data Reservoirs: The Diverse Data Goldmine
- Granular Insights: The vast and varied nature of Data Reservoirs allows businesses to dive deep into granular data. This might involve analyzing individual customer journeys, understanding micro-moments, or exploring niche market segments.
- Sentiment Analysis: By ingesting data from sources like social media or customer reviews, Data Reservoirs enable sentiment analysis. Businesses can gauge public perception, track brand sentiment, and respond to emerging trends or concerns.
- Real-time Decision Making: With the ability to process data in real-time, Data Reservoirs empower businesses to make decisions on-the-fly. This is crucial in scenarios like stock trading, e-commerce product recommendations, or fraud detection.
- Exploratory Analysis: The flexibility of Data Reservoirs makes them ideal playgrounds for exploratory data analysis. Businesses can experiment with new data sources, test hypotheses, or discover unexpected insights, fostering innovation.
Empowering Decision Makers
- Data Democratization: Making data accessible to non-technical stakeholders ensures that insights aren’t confined to data teams. Tools that simplify data querying, visualization, and interpretation empower decision-makers across the organization.
- Collaborative Decision Making: Integrating data systems with collaboration tools facilitates team-based decision-making. Stakeholders can discuss insights, share visualizations, and collectively chart the business’s course.
- Continuous Learning: As decisions are made and outcomes observed, it’s essential to feed these learnings back into the data systems. This iterative process refines models, improves forecasts, and ensures that the business evolves with the changing landscape.
In conclusion, while Data Warehouses provide structured, historical insights, Data Reservoirs offer a broader, more flexible view of the business landscape. Together, they equip businesses with a comprehensive data toolkit, ensuring that decisions are data-driven, informed, and aligned with organizational goals. In the age of information, leveraging these systems is key to business success and sustainability.
In today’s competitive business landscape, making informed decisions is not just a luxury—it’s a necessity. Both Data Warehouses and Data Reservoirs play pivotal roles in equipping businesses with the insights they need to navigate challenges and seize opportunities. Let’s explore how these systems influence and enhance business decision-making.
Data Warehouses: The Structured Insight Engine
- Historical Analysis: With their ability to store structured historical data, Data Warehouses enable businesses to look back in time. This retrospective view allows for trend analysis, year-over-year comparisons, and understanding past performance to predict future trajectories.
- Key Performance Indicators (KPIs): Data Warehouses often power Business Intelligence (BI) tools that track and visualize KPIs. Whether it’s sales metrics, customer retention rates, or operational efficiencies, these KPIs provide a pulse on the business’s health.
- Segmentation and Targeting: By analyzing customer data, businesses can segment their audience based on behavior, preferences, or demographics. This segmentation drives targeted marketing campaigns, personalized experiences, and tailored product offerings.
- Forecasting and Predictive Analysis: Using historical data as a foundation, Data Warehouses can support forecasting models. These models predict future sales, market demands, or inventory levels, helping businesses plan and allocate resources effectively.
Data Reservoirs: The Diverse Data Goldmine
- Granular Insights: The vast and varied nature of Data Reservoirs allows businesses to dive deep into granular data. This might involve analyzing individual customer journeys, understanding micro-moments, or exploring niche market segments.
- Sentiment Analysis: By ingesting data from sources like social media or customer reviews, Data Reservoirs enable sentiment analysis. Businesses can gauge public perception, track brand sentiment, and respond to emerging trends or concerns.
- Real-time Decision Making: With the ability to process data in real-time, Data Reservoirs empower businesses to make decisions on-the-fly. This is crucial in scenarios like stock trading, e-commerce product recommendations, or fraud detection.
- Exploratory Analysis: The flexibility of Data Reservoirs makes them ideal playgrounds for exploratory data analysis. Businesses can experiment with new data sources, test hypotheses, or discover unexpected insights, fostering innovation.
Empowering Decision Makers
- Data Democratization: Making data accessible to non-technical stakeholders ensures that insights aren’t confined to data teams. Tools that simplify data querying, visualization, and interpretation empower decision-makers across the organization.
- Collaborative Decision Making: Integrating data systems with collaboration tools facilitates team-based decision-making. Stakeholders can discuss insights, share visualizations, and collectively chart the business’s course.
- Continuous Learning: As decisions are made and outcomes observed, it’s essential to feed these learnings back into the data systems. This iterative process refines models, improves forecasts, and ensures that the business evolves with the changing landscape.
In conclusion, while Data Warehouses provide structured, historical insights, Data Reservoirs offer a broader, more flexible view of the business landscape. Together, they equip businesses with a comprehensive data toolkit, ensuring that decisions are data-driven, informed, and aligned with organizational goals. In the age of information, leveraging these systems is key to business success and sustainability.
4.2 Challenges and Solutions
Both Data Warehouses and Data Reservoirs, while powerful, come with their own set of challenges. Understanding these challenges and implementing effective solutions is crucial for organizations to harness the full potential of their data infrastructure.
Data Warehouses: Navigating the Structured Maze
- Challenge: Data Silos: Often, organizations have multiple Data Warehouses managed by different departments, leading to data silos. This fragmentation can hinder a unified view of business data.
- Solution: Implementing a centralized Data Warehouse or integrating multiple warehouses using data integration tools can break down these silos, ensuring a cohesive data landscape.
- Challenge: Performance Bottlenecks: As data volumes grow, query performance can degrade, leading to slower insights.
- Solution: Regularly optimizing the Data Warehouse, implementing indexing, partitioning, and leveraging in-memory processing can enhance performance.
- Challenge: Rigidity: Traditional Data Warehouses can be rigid, making it challenging to adapt to evolving data sources or business needs.
- Solution: Adopting modern Data Warehouse solutions that offer flexibility in data modeling and integration can address this challenge.
Data Reservoirs: Managing the Vast Expanse
- Challenge: Data Swamp: Without proper governance and quality checks, a Data Reservoir can quickly devolve into a “data swamp” – a chaotic repository with low-quality data.
- Solution: Implementing robust data governance frameworks, quality checks, and metadata management can ensure the reservoir remains organized and valuable.
- Challenge: Security Concerns: Storing diverse data, including potentially sensitive information, raises security and compliance concerns.
- Solution: Implementing robust access controls, encryption, and regular audits can safeguard data and ensure regulatory compliance.
- Challenge: Complexity: The vast and varied nature of Data Reservoirs can make them complex to navigate and manage.
- Solution: Using data cataloging tools, visualization platforms, and training teams on best practices can simplify reservoir management.
Universal Challenges and Solutions
- Challenge: Skill Gap: The specialized nature of data systems often requires expertise that may not be readily available within organizations.
- Solution: Investing in training programs, workshops, and hiring or partnering with experts can bridge this skill gap.
- Challenge: Data Integration: Integrating data from diverse sources, each with its own format and structure, can be challenging.
- Solution: Leveraging data integration platforms, ETL tools, and adopting standardized data formats can streamline integration.
- Challenge: Cost Management: Managing and scaling data infrastructure can lead to escalating costs.
- Solution: Adopting cloud-based solutions that offer pay-as-you-go pricing, optimizing storage and queries, and monitoring usage can help manage costs effectively.
In conclusion, while challenges are inherent to any technology or system, proactive identification and strategic solutions can mitigate these challenges. For Data Warehouses and Data Reservoirs, the key lies in balancing flexibility with governance, innovation with security, and exploration with optimization. By addressing these challenges head-on, organizations can unlock the true potential of their data infrastructure, driving insights, innovation, and growth.
4.3 Future Trends
As the digital landscape continues to evolve, so do the technologies and methodologies surrounding data management. Here’s a glimpse into the potential future trends for Data Warehouses and Data Reservoirs:
Data Warehouses: Beyond Traditional Boundaries
- Cloud-Native Warehouses: As businesses increasingly migrate to the cloud, we can expect a surge in cloud-native Data Warehouses. These solutions offer scalability, flexibility, and cost-effectiveness, catering to dynamic business needs.
- Real-time Analytics: While Data Warehouses have traditionally been batch-oriented, there’s a growing demand for real-time insights. Future warehouses might incorporate streaming data capabilities to support instantaneous analytics.
- Integration with AI and ML: Advanced analytics powered by Artificial Intelligence (AI) and Machine Learning (ML) will become more integrated with Data Warehouses. This will allow for predictive modeling, anomaly detection, and more, right within the warehouse environment.
- Enhanced Security: With rising concerns about data breaches and privacy regulations, future Data Warehouses will likely incorporate more advanced security measures, including AI-driven threat detection and automated compliance checks.
Data Reservoirs: The Age of Refinement
- From Reservoirs to Lakes: The concept of Data Lakes, which combines the vast storage capabilities of reservoirs with more structured analytical features, will gain prominence. This evolution will focus on balancing raw data storage with actionable insights.
- Automated Data Governance: As Data Reservoirs grow, manual governance will become untenable. We can expect advancements in automated governance tools that ensure data quality, lineage tracking, and metadata management.
- Edge Computing Integration: With the rise of IoT devices, processing data at the edge (closer to data sources) will become crucial. Data Reservoirs will likely integrate more closely with edge computing solutions, enabling more efficient data ingestion and analytics.
- Semantic Search and Cataloging: To enhance data discoverability, future reservoirs might incorporate semantic search capabilities. This will allow users to find datasets based on context and intent, rather than just keywords.
Unified Data Ecosystems
- Convergence of Warehouses and Reservoirs: As the lines between structured and unstructured data blur, we might see a convergence of Data Warehouses and Reservoirs, leading to unified data platforms that offer the best of both worlds.
- Data Marketplace: The idea of data marketplaces, where organizations can buy, sell, or share datasets, might gain traction. This will be facilitated by advanced data platforms that ensure data quality, security, and compliance.
- Sustainability and Green Computing: As environmental concerns rise, there will be a push towards making data centers and infrastructure more sustainable. Energy-efficient hardware, optimized queries, and green computing practices will become standard.
In essence, the future of Data Warehouses and Data Reservoirs is poised to be dynamic, innovative, and centered around delivering value. As technology continues to advance and business needs evolve, these data systems will adapt, ensuring that organizations remain data-driven, agile, and ready for the challenges of tomorrow.
Conclusion: The Convergence
The worlds of Data Warehouses and Data Reservoirs, while distinct in their origins and purposes, are on a path of inevitable convergence. As businesses grapple with the complexities of modern data landscapes, the need for a unified, holistic approach to data management becomes paramount. Let’s explore the contours of this convergence and what it signifies for the future of data.
Blurring Boundaries
- Unified Data Platforms: The future likely holds the emergence of platforms that combine the structured, analytical prowess of Data Warehouses with the vast, flexible storage capabilities of Data Reservoirs. These unified platforms will offer businesses a one-stop solution for all their data needs.
- Hybrid Architectures: Instead of choosing between a warehouse or a reservoir, organizations will adopt hybrid architectures. These systems will seamlessly integrate structured and unstructured data, ensuring comprehensive analytics without compromising on data richness.
- Schema Flexibility: The rigid schema-on-write approach of traditional warehouses and the flexible schema-on-read of reservoirs might give way to adaptive schema mechanisms. These will allow data structures to evolve based on usage patterns and business needs.
Enhanced Capabilities
- Real-time Analytics: The convergence will facilitate real-time analytics at scale. Whether it’s streaming data from IoT devices or instantaneous business metrics, the unified platforms will be equipped to handle and analyze data in real-time.
- Advanced AI Integration: With a holistic view of data, these converged systems will better integrate with AI and ML models. This will enable more accurate predictions, smarter automations, and enhanced user experiences.
- Data Governance 2.0: The combined platforms will usher in a new era of data governance. Automated tools powered by AI will ensure data quality, lineage, and compliance, making governance more proactive and less reactive.
Implications for Businesses
- Cost Efficiency: By consolidating data infrastructure, businesses can achieve better cost efficiencies. Reduced redundancy, optimized storage, and streamlined operations will lead to significant cost savings.
- Agility and Innovation: With a unified data platform, businesses can be more agile. Rapid prototyping, iterative analytics, and faster insights will drive innovation at an unprecedented pace.
- Empowered Decision-making: Decision-makers will have access to richer, more comprehensive datasets. This will lead to more informed decisions, aligning closely with business goals and market realities.
In wrapping up, the convergence of Data Warehouses and Data Reservoirs is not just a technological evolution—it’s a strategic imperative. As data continues to be the lifeblood of modern businesses, this union promises a future where data is not just managed but harnessed, not just stored but leveraged, and not just analyzed but actualized. The future of data is unified, and it’s a future full of promise.

